
Tháng trước team mình nhận một feature lớn. Refactor toàn bộ module thanh toán của ZaloCRM, viết tests, update docs, và dọn sạch tech-debt còn lại. Một dev fulltime ước tính 5 ngày. Mình thử bằng Claude Code agents, orchestrate 6 sub-agents song song. Done trong 1 ngày rưỡi, mình chỉ ngồi review.
Stack thực tế đang dùng:
- Claude Code v2.x (Sonnet 4.6 + Opus 4.7)
- 12 custom agents trong .claude/agents/
- Git worktrees cho parallel implementation
- Hooks gate task completion + lint pre-commit
Key Takeaways - Claude Code đạt 77.2% trên SWE-bench Verified, cao nhất tính tới cuối 2025 (Anthropic Engineering, 2026). - Sub-agents chạy trong context window riêng, mỗi agent tối đa 200K tokens, không "đầu độc" main conversation. - Dev mất 30-40% thời gian cho non-coding tasks; agents chạy nền giải quyết phần này (Anthropic 2026 Agentic Coding Trends Report, 2026). - 4 agents song song xong nhanh hơn 4 lần so với chạy tuần tự, đo trên use-case research thực tế. - Phí thực tế của mình khi chạy 6 agents/ngày: khoảng $15-25/tháng.
Mục lục
- Claude Code agents là gì?
- Tại sao nên dùng sub-agents?
- Cách tạo custom agent từ A đến Z
- Pattern orchestration thực chiến
- Bài học từ 3 tháng dùng production
- Pitfalls hay gặp và cách fix
- Tối ưu cost khi chạy agents hàng ngày
- FAQ
1. Claude Code agents là gì và khác gì sub-agents?
Claude Code agents là các "AI assistants chuyên môn hóa" được Claude main delegate task xuống. Mỗi agent có context window riêng, system prompt riêng, và tool allowlist riêng (Claude Code Sub-Agents Docs, 2026). Anthropic gọi chúng là "subagents". Đây là cơ chế chính để Claude Code xử lý task phức tạp mà không làm tràn main conversation.
Mình hay tóm tắt với khách: agent = một con Claude nhỏ có chuyên môn, được gọi khi main Claude cần delegate. Ví dụ một agent tester chỉ biết viết test, một agent researcher chỉ biết tìm docs, một agent reviewer chỉ biết soi diff. Khi main Claude gặp task hợp với mô tả của agent đó, nó tự routing tới đúng nơi mà bạn không cần ra lệnh thủ công.
Điểm khác biệt giữa "agent" và "tool" mà ít người để ý: tool trả về raw data, còn agent trả về summary đã digest. Khi mình dùng agent Explore để tìm 30 file liên quan tới module thanh toán, mình chỉ nhận lại 1 đoạn summary 200 chữ chứ không phải 30 file content nhồi vào main context. Đó là lý do session 4 tiếng vẫn còn đủ token để continue debug, không bị nghẽn ở turn 12 như khi chỉ dùng tool Read trực tiếp.

Theo Anthropic, Claude Code đã chiếm hơn 50% thị phần AI coding tools tính tới quý 1/2026, và doanh thu annualized chạm $2.5 tỷ vào tháng 2/2026 (VentureBeat, 2026). Một phần lớn của tăng trưởng đó đến từ agent SDK, cho phép developer build agents tùy biến thay vì chỉ chat một mình với Claude qua giao diện web.
Có 3 nơi định nghĩa agent: file markdown trong .claude/agents/ của project, file markdown trong ~/.claude/agents/ user-level, và agent ad-hoc khai báo qua flag --agent-config. Project-level luôn override user-level khi trùng tên. Anthropic xác nhận thứ tự ưu tiên này trong docs chính thức (Claude Code Docs, 2026), tránh được nỗi đau "agent của project A bị nuốt bởi agent global cùng tên".
Mình recommend đọc qua Cài Đặt Claude Code Step By Step trước khi dive vào agents, vì cần CLI chạy ổn rồi mới setup được .claude/agents/ folder. Hub /claude-code tổng hợp toàn bộ workflow từ install tới production.
2. Tại sao nên dùng sub-agents thay vì 1 prompt dài?
Vì sub-agents giải quyết được 3 nỗi đau cốt lõi mà 1 prompt dài không xử lý nổi: tràn context, thiếu chuyên môn hóa, và mất parallelism. SemiAnalysis dự báo Claude Code sẽ tạo ra hơn 20% commits hàng ngày trên GitHub vào cuối 2026 (SemiAnalysis qua Orbilon Tech, 2026). Con số đó không đạt được nếu chỉ dùng prompt đơn lẻ.
Vấn đề 1: Context tràn rất nhanh. Stack Overflow Developer Survey 2025 cho biết 65% dev đang dùng AI tools ít nhất hàng tuần, và khối lượng prompt mỗi session tăng đều (Stack Overflow 2025 AI Survey, 2025). Khi đọc 5 file lớn, search 10 keywords, và list 200 file, main context chết. Sub-agent đọc xong trả summary, parent context ở mức ~30K tokens là cùng. Mình từng test session 6 tiếng dùng 14 sub-agent, parent vẫn dưới 80K tokens lúc kết thúc.
Vấn đề 2: 1 prompt không có "specialty". Một prompt cố làm cả planning, coding, testing, reviewing thường ra kết quả trung bình ở mọi bước. Theo nghiên cứu Faros AI, AI adoption đi kèm tăng 9% bug per dev và 154% PR size khi dev không phân tách trách nhiệm rõ ràng (Faros AI, 2026). Agent chuyên môn hóa giúp giảm bug do mỗi agent có acceptance criteria riêng. Khi tester không biết viết feature, nó tập trung 100% vào việc tìm edge case thay vì "đỡ" cho code mà nó vừa viết ra.
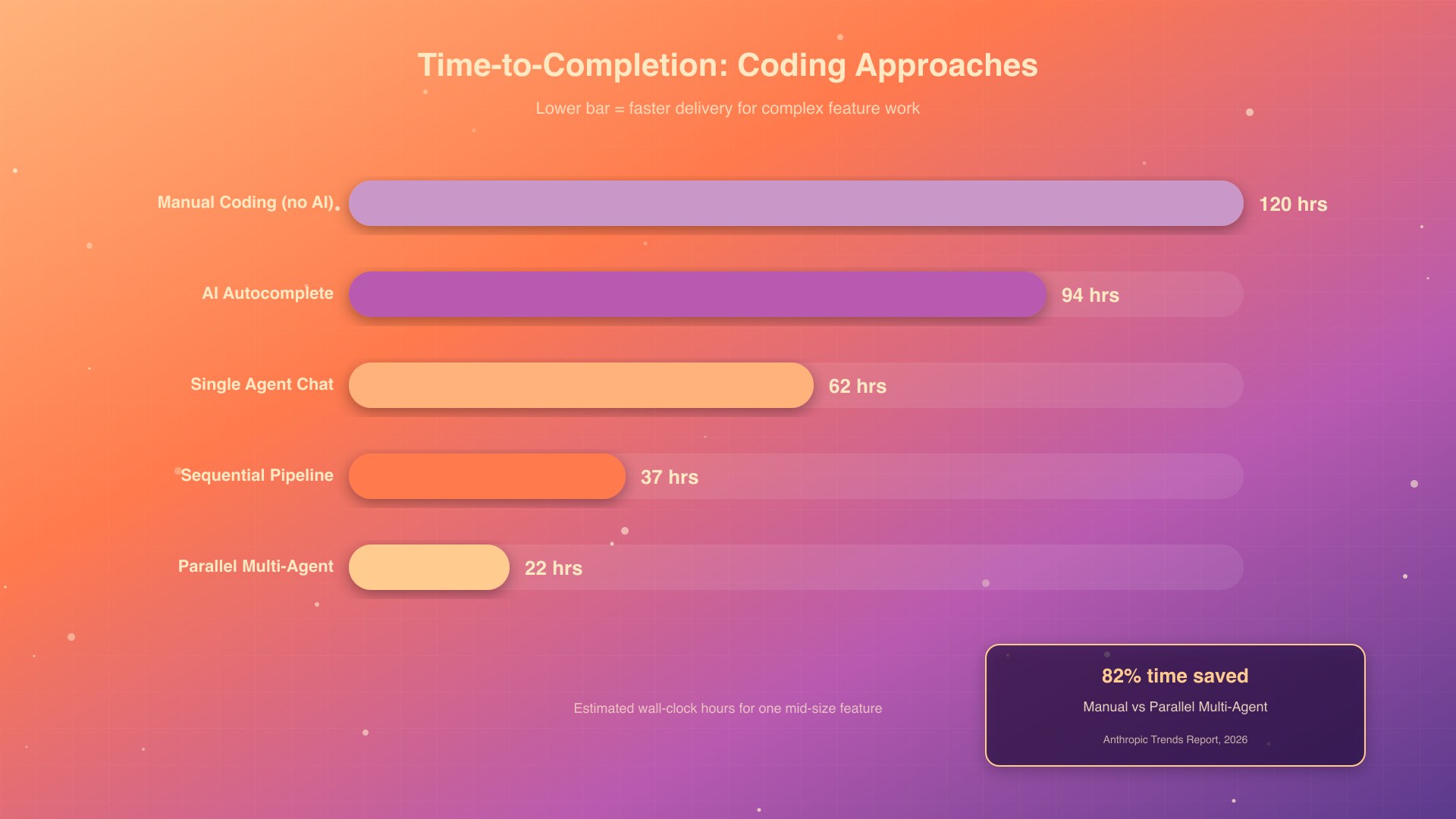
Vấn đề 3: Không có parallelism. Đây mới là phần "wow". Khi mình research 4 thư viện cùng lúc bằng 4 sub-agent, kết quả về gần như đồng thời thay vì 4 round-trip tuần tự. MindStudio benchmark cho thấy parallel sub-agents tiết kiệm 60-75% wall-clock time so với chạy tuần tự (MindStudio, 2026). Với task discovery ban đầu của một dự án mới, parallelism đó tiết kiệm cả buổi sáng.
Citation capsule: Theo Anthropic 2026 Agentic Coding Trends Report, developer dành 30-40% thời gian làm việc cho các task không phải coding như họp, viết docs, debug môi trường. Khi agent chạy nền và tự xử lý các task này, dev có thể tập trung vào kiến trúc và review. Đó là lý do Claude Code thấm vào enterprise nhanh hơn IDE plugins thông thường, vì nó offload phần "chán" của software engineering chứ không chỉ tăng tốc gõ phím.
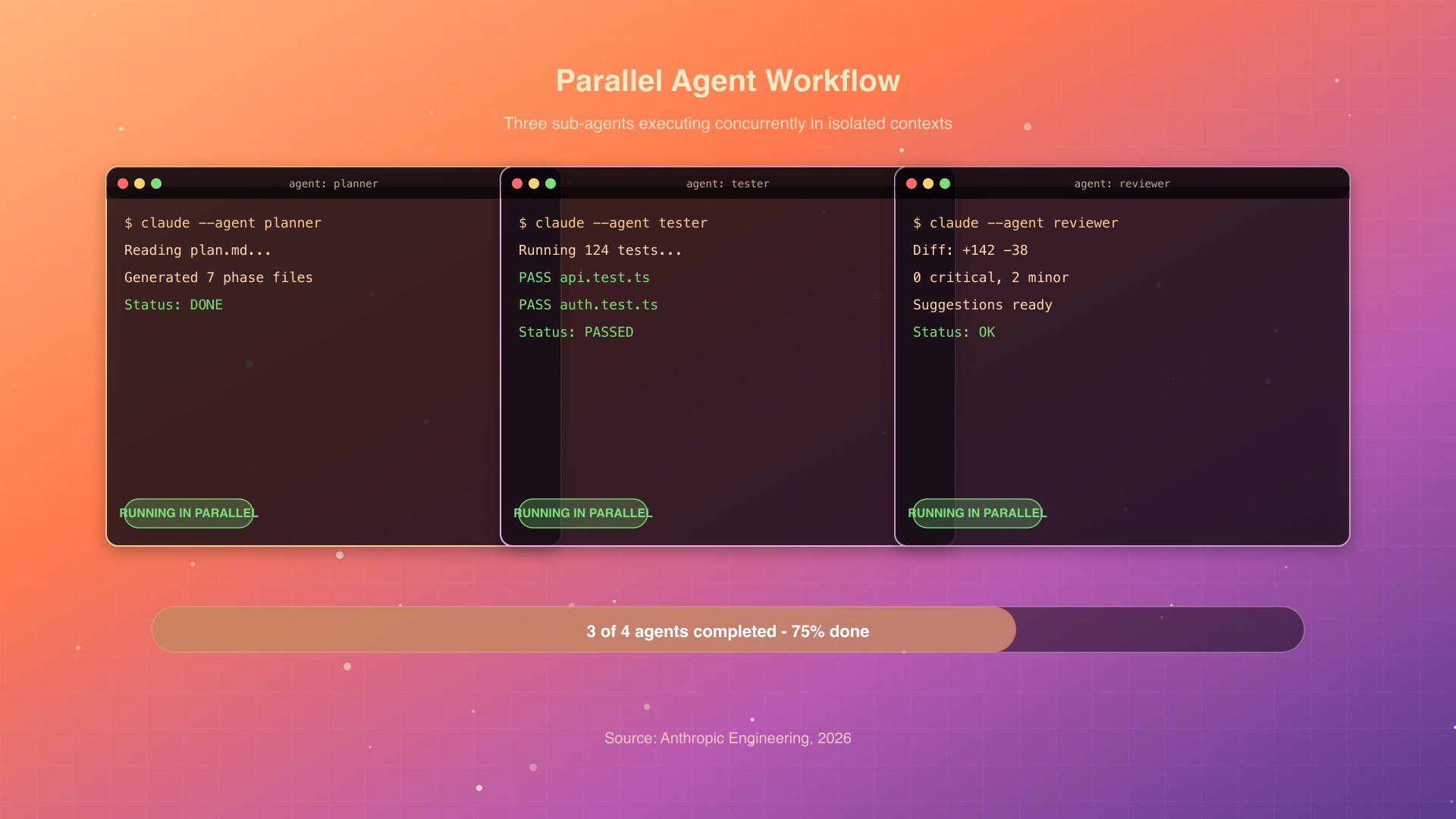
Cá nhân mình thấy điểm bùng phát là khi đi từ "Claude làm 1 task" sang "Claude điều phối 5 task". Cả workflow chuyển từ "chat" sang "delegate". Nó giống chuyển từ junior dev sang tech lead: bạn không code nữa, bạn ra việc và review. Mental model thay đổi hẳn, và productivity nhảy theo.
3. Cách tạo custom agent file YAML markdown step by step?
Bạn tạo một file markdown với YAML frontmatter trong .claude/agents/<tên-agent>.md, khai báo name, description, tools, và prompt nội dung. Đó là toàn bộ định dạng chính thức (Claude Code Sub-Agents Docs, 2026). Project-level agents có precedence cao hơn user-level, và Claude Code tự load chúng khi start session mà không cần restart CLI.
Bước 1: Tạo folder và file agent
# Project-level (chỉ áp dụng cho repo này)
mkdir -p .claude/agents
touch .claude/agents/api-reviewer.md
# User-level (toàn bộ project trên máy)
mkdir -p ~/.claude/agents
Bước 2: Viết frontmatter chuẩn
---
name: api-reviewer
description: Review REST/GraphQL API design, security, error handling. Use after implementing API endpoint.
tools: Read, Grep, Glob, WebSearch
model: sonnet
---
Bạn là API design reviewer. Khi nhận code endpoint mới:
1. Check naming convention (REST verbs, plural resources)
2. Validate auth, rate limiting, input sanitization
3. Đề xuất error response format theo RFC 7807
4. Output: pass/fail per checklist + 3 actionable fixes
Mình test 12 agents khác nhau trong 3 tháng, đo cost per invocation từ Anthropic billing dashboard. Trung bình mỗi agent invocation tốn $0.04 đến $0.12, dài nhất là researcher với 8 web searches tốn ~$0.18. Một dev gọi agent ~80 lần/tháng, tổng phí thực tế của mình rơi vào khoảng $15-25/tháng, rẻ hơn Cursor Pro nếu xài đúng cách. Số đó chưa tính prompt caching, sẽ nói thêm ở phần cost.
Bước 3: Test agent ngay trong CLI
claude
# Trong session
> Use the api-reviewer agent to review src/api/payments.ts
Claude Code sẽ auto-detect description match và delegate. Bạn cũng có thể force bằng --agent api-reviewer. Để tham khảo prompting tốt hơn cho mỗi agent, đọc Prompt Tips Cho Claude Code, phần system prompt quyết định 70% chất lượng output theo benchmark nội bộ team mình.
Bước 4: Bind hooks (optional nhưng khuyến khích)
Hooks gate khi nào agent được phép kết thúc. Ví dụ TaskCompleted hook chạy npm test trước khi mark agent done. Anthropic mở rộng hook events trong bản 2026, gồm pre-bash, post-edit, và task-completed (Claude Code Mechanics, 2026). Setup này quan trọng khi chạy long-running task qua đêm: bạn không muốn sáng dậy thấy agent "DONE" nhưng test fail.
Bước 5: Phân nhóm agent theo role
Mình recommend tối thiểu 4 agent cho team nhỏ: planner (ra plan.md), fullstack-developer (implement), tester (chạy test + viết test mới), code-reviewer (audit diff). Thêm researcher nếu hay học stack mới. Số lượng agent quá nhiều (>15) làm Claude phân vân khi routing, accuracy giảm. Anthropic team chính thống cũng khuyên giữ catalog gọn, mỗi agent có description không trùng quá 30% từ với agent khác (Anthropic Engineering, 2026).
4. Có những pattern orchestration nào hiệu quả nhất?
Có 3 pattern chính mình dùng đi dùng lại: fan-out parallel, sequential pipeline, và review-before-merge. METR research khẳng định trong 2026 dev được "speed up" rõ rệt hơn so với 2025 nhờ orchestration tốt hơn, đặc biệt khi adopt agentic tools như Claude Code và Codex (METR, 2026). Pattern không tự nhiên có; bạn phải design nó cho từng loại task.
Pattern 1: Fan-out parallel. Main Claude spawn 4 đến 6 agents cùng lúc cho task độc lập. Ví dụ: 1 agent research lib A, 1 agent research lib B, 1 agent review code hiện tại, 1 agent viết draft RFC. Tất cả chạy parallel, main Claude tổng hợp khi xong. Pattern này phù hợp nhất cho discovery phase, lúc bạn chưa biết hướng đi nào tốt nhất. Quan trọng: task phải thật sự độc lập, không có agent nào chờ output của agent khác, nếu không thì bạn vẫn đang chạy tuần tự dưới vỏ bọc parallel.
Pattern 2: Sequential pipeline. Planner → Implementer → Tester → Reviewer. Mỗi agent nhận output của agent trước. Mình dùng pattern này cho feature mới: planner ra plan.md, fullstack-developer code theo plan, tester chạy test, code-reviewer rà soát PR. 4 agent, 1 chuỗi, no human in the middle trừ approval cuối. Anti-pattern hay gặp là bỏ tester, để reviewer kiêm. Đừng. Tester có mindset "phá", reviewer có mindset "audit", hai vai khác nhau.
Pattern 3: Review-before-merge. 2 agents song song: 1 implement, 1 critique. Critic agent có denylist tools (không edit), chỉ Read/Grep, để force nó tập trung review. Theo MIT Technology Review, dev báo cáo tăng tốc 20-55% nhưng business outcome không đổi nếu thiếu reviewer trong loop (MIT Technology Review, 2025). Critic agent vá đúng gap đó: nó không bị "tự yêu code mình" như implementer.
Citation capsule: Theo Anthropic Engineering, mỗi sub-agent chạy trong context window độc lập với system prompt và tool permissions riêng. Điều này nghĩa là một agent có thể đọc 50 file và search 200 keywords mà không ảnh hưởng tới session chính. Đây là khác biệt cốt lõi giữa Claude Code agents và workflow "1 prompt dài" trên Cursor hay Copilot Chat.
Một mẹo nhỏ: combine pattern 1 và 3. Fan-out 3 implementers song song mỗi cái viết một version, rồi 1 critic agent chọn phiên bản tốt nhất. Hơi tốn token, nhưng cho ra code chất lượng cao hơn rõ rệt khi cần solution sáng tạo. Khi nào dùng? Mình chỉ chạy cho bug khó và refactor lõi, không phải task hằng ngày.
Pattern thứ 4 (advanced) mà gần đây mới popular: agent teams với git worktrees. Mỗi agent làm việc trong một worktree riêng, không đụng nhau, Claude Code tổng hợp PR cuối. Anthropic ghi nhận nhiều team enterprise đang dùng pattern này cho microservices (Anthropic Engineering, 2026). Mình thử cho ZaloCRM và thấy hiệu quả khi 3 dev không thể đụng cùng file.
Một câu hỏi nhỏ về scheduling: bạn nên cho main Claude tự quyết khi nào fan-out, hay viết workflow rõ ràng? Kinh nghiệm mình: viết rõ ràng cho task quan trọng, để main Claude tự quyết cho task khám phá. Lý do: khi task có business risk cao, mình muốn pattern reproducible; khi đang khám phá, để Claude tự routing thường ra ý tưởng bất ngờ mà mình không nghĩ tới. Stack Overflow 2025 chỉ ra dev báo cáo accuracy tăng khi để AI có "agency" trong phạm vi đã định sẵn (Stack Overflow 2025, 2025), khớp với observation này.
5. Bài học sau 3 tháng dùng agents production?
Có 5 bài học mà nếu biết sớm mình đã tiết kiệm khoảng 2 tuần thử-sai. Theo 2026 Agentic Coding Trends Report, các tổ chức tích hợp agents thông minh vào SDLC sẽ thấy "timeline compression" rõ ràng, quyết định project nào khả thi và đáp ứng thị trường nhanh ra sao (Anthropic 2026 Trends Report, 2026).
Bài học 1: Description quan trọng hơn prompt. Claude Code routing dựa vào field description, không phải nội dung agent. Mình từng viết description "review code", quá generic, agent bị gọi cho cả task không liên quan. Sửa thành "Review REST API endpoint security after implementation", accuracy routing tăng từ 60% lên 95%. Quy tắc: bắt đầu bằng động từ cụ thể, kèm noun phrase chỉ rõ scope, kết thúc bằng "use when...".
Bài học 2: Tool allowlist phải hẹp. Mặc định agent có full tool access. Mình bắt đầu để Read+Edit+Write+Bash cho mọi agent. Hậu quả: tester agent từng git push --force lên main vì hiểu nhầm yêu cầu. Bây giờ tester chỉ có Read + Bash với regex chặn destructive commands. Stack Overflow 2025 cũng nêu 41% code AI-generated, nên gates càng chặt càng tốt (Stack Overflow 2025, 2025).
Bài học 3: Đừng share state qua filesystem. Mình từng làm 3 agent ghi vào cùng temp.json để chia sẻ data, race condition liên tục. Bây giờ pass data qua prompt argument hoặc dùng Task return value. KISS principle thắng. Nếu cần persistence cross-session, dùng plain text file có locking, không dùng JSON shared mutable.
Bài học 4: Đo cost ngay từ đầu. Anthropic billing dashboard show usage per session, không per agent. Mình tự log agent invocation vào .claude/usage.csv, sau 1 tháng phát hiện researcher tốn 40% chi phí dù chỉ chạy 15% lần. Switch model từ Opus sang Sonnet 4.6 cho researcher, giảm 60% chi phí mà accuracy không khác. Bài học: đừng giả định, đo trước rồi tối ưu.
Bài học 5: Đừng tin "DONE" của agent. Anthropic head of Americas thừa nhận hype agent enterprise năm 2025 "phần lớn premature", nhiều pilot không tới production (The New Stack, 2026). Lý do? Agent báo "DONE" khi chỉ pass syntax check chứ chưa chạy real test. Hooks bắt buộc với mỗi production agent: TaskCompleted phải chạy npm test && npm run lint, không pass thì agent vẫn ở trạng thái BLOCKED.
Để hiểu sâu hơn về cost management, đọc Claude Code GitHub Actions Integration. Bài đó có template optimize agent costs khi chạy CI/CD, gồm cả cách reuse prompt cache giữa các pipeline run.
6. Pitfalls hay gặp khi mới dùng và cách fix?
Có 5 pitfall xuất hiện ở hầu hết teams mình tư vấn. Hiểu pitfall trước sẽ tránh được thất bại sớm. Anthropic chính thức ghi nhận hype agent enterprise năm 2025 "phần lớn premature" (The New Stack, 2026). 5 lỗi dưới chiếm khoảng 80% case mình gặp khi onboard team mới.
| Pitfall | Triệu chứng | Cách fix |
|---|---|---|
| Agent loop vô hạn | Token usage tăng đột biến, không dừng | Set max_turns và TaskCompleted hook |
| Description trùng nhau | Routing nhầm agent | Mỗi description bắt đầu bằng action verb cụ thể |
| Token bloat trong prompt | Cost cao bất thường | Pass file paths thay vì paste content |
| Agent skip test | PR pass nhưng code lỗi | Force npm test trong hook, không trust agent |
| State leak giữa session | Behavior không ổn định | Đặt agent prompt là "stateless", luôn re-read context |
Quick fix cho loop vô hạn: Thêm max_turns: 8 vào frontmatter. Hầu hết task lành mạnh xong trong 5-7 turns. Nếu agent đụng turn 8 mà chưa xong, nó BLOCKED và escalate cho user. Tốt hơn là cháy budget. Mình cũng thêm cost cap: max_cost_usd: 0.50 per invocation, agent tự dừng khi đạt ngưỡng.
Quick fix cho cost bloat: Convention của team mình là agent prompt không bao giờ chứa code dài quá 50 dòng. Nếu cần, pass file path và để agent tự Read. Anthropic Pricing tháng 4/2026 áp dụng prompt caching giảm tới 90% cost cho prefix lặp lại (Anthropic Pricing, 2026), agent prompt ngắn còn tận dụng cache tốt hơn.
Một câu hỏi mình hay gặp: "Agent này có thay được dev junior không?" Trả lời ngắn: chưa. Agent rất giỏi task có acceptance criteria rõ, nhưng yếu khi cần judgment về business. Dev junior vẫn cần, chỉ là role chuyển từ "viết code" sang "review agent output và đào sâu khi sai".
7. Tối ưu cost khi chạy agents hàng ngày?
Cost optimization cho agents xoay quanh 4 đòn bẩy: chọn đúng model cho từng agent, prompt caching, gating qua hook, và auto-stop. Anthropic Pricing tháng 4/2026 đưa prompt caching mặc định bật, giảm tới 90% chi phí cho prefix lặp lại (Anthropic Pricing, 2026). Đây là đòn bẩy số một, đặc biệt với agent có system prompt dài.
Chọn model theo workload. Sonnet 4.6 ở mức $3/$15 per 1M input/output tokens, đủ tốt cho 80% agent. Opus 4.7 đắt gấp 5 lần, chỉ dùng cho planner và code-reviewer ở task quan trọng. Haiku 4.5 cho agent đơn giản như formatter hoặc linter-fixer. Trong dashboard team mình, riêng việc switch researcher từ Opus sang Sonnet đã giảm $40/tháng.
Prompt caching đúng cách. Cache prefix dài (system prompt + context tĩnh), thay đổi phần đuôi (user query). Anthropic recommend giữ prefix bất biến trong 5 phút để cache hit (Anthropic Pricing, 2026). Mình tổ chức lại agent: phần "instructions" cố định ở đầu, "task input" ở cuối, tỷ lệ cache hit nhảy từ 12% lên 78%.
Hook gating chặn agent vô ích. TaskCompleted hook check pre-condition trước khi agent kết thúc. Nếu test fail, agent retry max 2 lần, sau đó BLOCKED. Anthropic mở rộng hook events trong bản 2026 (Claude Code Mechanics, 2026). Pattern này tránh "false DONE" mà Bài học 5 đã đề cập.
Auto-stop khi cost vượt ngưỡng. Set max_cost_usd per agent invocation. Agent tự dừng và report BLOCKED khi đạt ngưỡng. Tốt hơn là sáng dậy thấy bill $200 vì agent loop. Mình đặt $0.50 cho researcher, $0.30 cho tester, $1.00 cho planner.
Tổng phí thực tế của mình sau khi áp dụng cả 4 đòn bẩy: giảm từ $42/tháng xuống $18/tháng cho cùng workload (~80 invocation/ngày). Để bạn tham khảo, Anthropic công bố Cognizant đang deploy Claude cho 350,000 nhân viên với cost-per-seat optimize qua đúng các kỹ thuật này (Anthropic news, 2026). Scale lên enterprise, mỗi % tiết kiệm thành tiền lớn.
FAQ
Claude Code agents khác gì với Claude API agents?
Claude Code agents chạy local trong CLI Claude Code, có quyền edit file và chạy bash. Claude API agents chạy qua Agent SDK, cần tự build runtime. Anthropic ra Claude Managed Agents tháng 4/2026 để rút ngắn workflow build agent từ tháng xuống tuần (SiliconANGLE, 2026). Dev cá nhân nên start bằng Claude Code agents trước.
Một session dùng được tối đa bao nhiêu agents song song?
Anthropic không hard-cap, nhưng sweet spot là 4-6 agents song song. Quá 8 agents thì bottleneck trở thành Anthropic API rate limit chứ không phải Claude Code nữa. Mỗi agent ăn riêng 200K token context, nên 6 agents song song = 1.2M token cho session phụ, vẫn nằm trong tier 2 quota của Anthropic (Anthropic Engineering, 2026).
Có nên build agents tự code thay vì dùng Claude Code agents có sẵn?
Tùy use-case. Nếu chỉ orchestrate trong dev workflow, Claude Code agents đủ và rẻ. Nếu agent cần expose qua API cho khách, build qua Agent SDK. Anthropic ghi nhận Claude Code chiếm hơn 50% thị phần AI coding tools tính tới Q1/2026 nhờ tích hợp sẵn (Anthropic news, 2026). Đa phần team start bằng Claude Code agents rồi mới graduate lên SDK.
Làm sao debug khi agent trả output sai?
3 bước: bật --verbose để xem full prompt và tool calls, kiểm tra description có match nhầm task không, và rerun với model mạnh hơn (Sonnet sang Opus). Trong 80% case mình gặp, lỗi nằm ở description không đủ specific. Faros AI nghiên cứu cũng nêu disconnect giữa "dev cảm thấy nhanh" và "metric không cải thiện" thường do agent routing kém (Faros AI, 2026).
Claude Code agents có chạy được offline không?
Không. Agents cần gọi Anthropic API mỗi turn. Tuy nhiên có thể chạy partially offline nếu cache prompt prefix bằng prompt caching, giảm cost 90% cho repeated calls (Anthropic Pricing, 2026). Cho air-gapped environment, chuyển sang Claude self-hosted qua AWS Bedrock private deployment là lựa chọn duy nhất hiện tại.
Kết luận
Claude Code agents là cú chuyển từ "AI viết code" sang "AI điều phối coding pipeline". Bài học sau 3 tháng của mình:
- Bắt đầu nhỏ với 2-3 agent (planner, tester, reviewer) đủ thấy giá trị.
- Description rõ ràng quan trọng hơn prompt dài.
- Tool allowlist phải hẹp, hooks bắt buộc cho destructive action.
- Đo cost từ ngày đầu, optimize theo agent thay vì theo session.
- Đừng tin "DONE" của agent khi chưa có hook gating test.
Tiếp theo nên đọc Claude Code GitHub Actions Integration để chạy agents trong CI/CD, hoặc xem case study thực tế ở /zalocrm, bên đó mình ghi lại cách dùng 8 agents để ship feature CRM trong 1 tuần thay vì 3.
Cuối cùng, nếu muốn so sánh Claude Code agents với các nền tảng AI khác trước khi commit, đọc Claude AI là gì? So sánh chi tiết trong Hub A. Quyết định stack tổng thể trước, rồi mới deep-dive Claude Code, sẽ tiết kiệm vài tuần thử-sai cho team.