Đầu năm nay, một chủ doanh nghiệp logistics hỏi mình: "Anh ơi, mình có 500 trang quy trình nội bộ. Nhân viên mới cứ hỏi đi hỏi lại mấy câu cơ bản mà senior mệt mỏi lắm. Có cách nào để AI đọc hết tài liệu đó rồi tự trả lời không?"
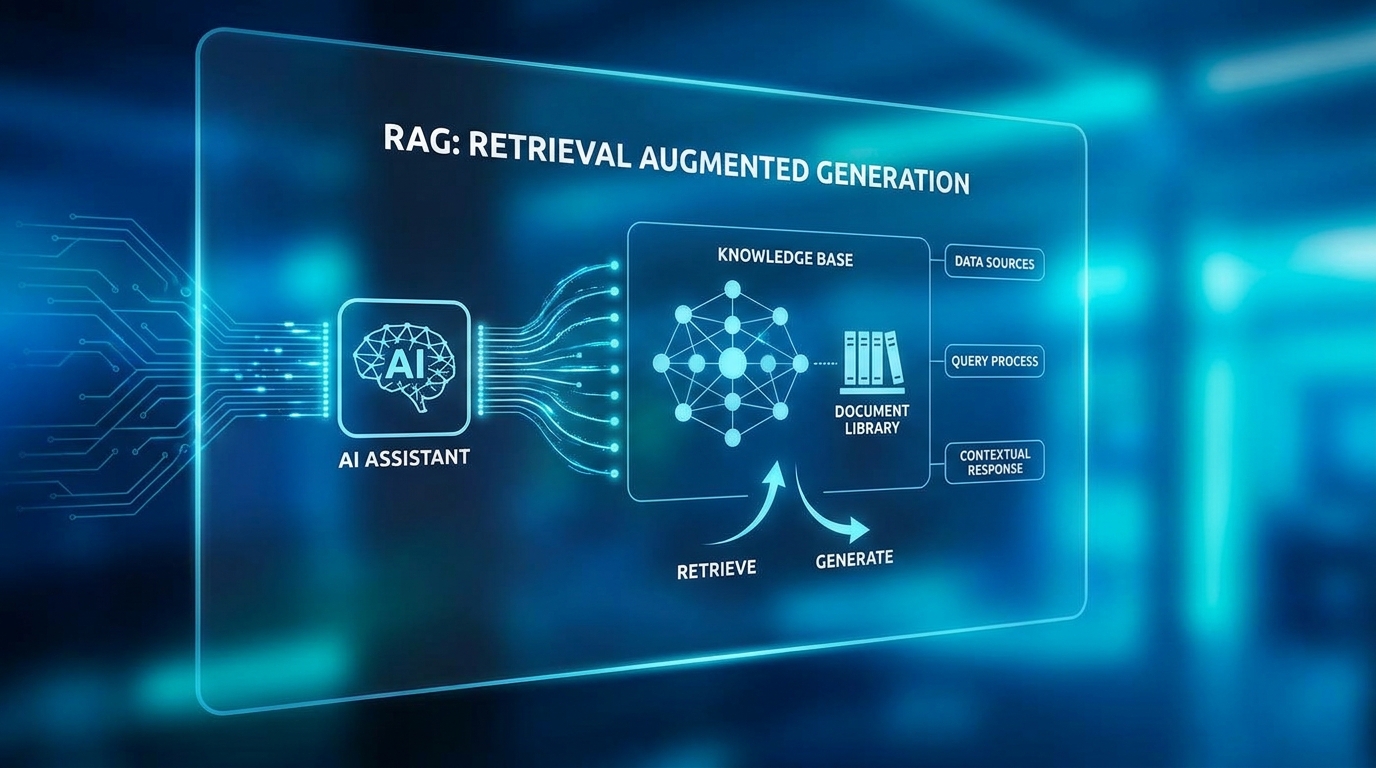
Câu trả lời là: có. Tên gọi của giải pháp đó là RAG (Retrieval Augmented Generation). Đây cũng là thứ mình đã build cho 3 SME Việt trong 6 tháng qua.
Bài này giải thích RAG theo cách không cần background kỹ thuật để hiểu, nhưng đủ sâu để bạn ra quyết định xem có nên đầu tư vào nó không.
Key Takeaways - Thị trường RAG toàn cầu đạt 2.33 tỷ USD năm 2025 và dự kiến lên 3.33 tỷ USD năm 2026 (Next MSC, 2026). - 80% lập trình viên enterprise coi RAG là cách tốt nhất để ground LLM bằng dữ liệu thật (Vectara, 2025). - RAG kéo tỉ lệ hallucination từ 20-40% xuống dưới 5% trong môi trường production (Kernshell, 2026). - Setup RAG cho SME Việt: 5-50 triệu VND. Vận hành: 1-2.2 triệu/tháng. Hoàn vốn thường trong 1-2 tháng.
Mục lục
- RAG là gì? Giải thích không kỹ thuật
- RAG hoạt động như thế nào? 4 bước cơ bản
- RAG vs AI thường khác nhau ở đâu?
- RAG vs Fine-tuning: nên chọn cái nào?
- 3 use case nào phù hợp nhất cho SME Việt?
- Chi phí thực tế của một dự án RAG là bao nhiêu?
- Bắt đầu build RAG đầu tiên thế nào?
- FAQ
1. RAG là gì? Giải thích không kỹ thuật
RAG (Retrieval Augmented Generation) là kỹ thuật cho phép AI đọc tài liệu của bạn rồi trả lời dựa trên nội dung đó, thay vì chỉ dùng kiến thức training. Theo khảo sát Vectara, 80% lập trình viên enterprise coi đây là cách hiệu quả nhất để ground LLM bằng dữ liệu thật (Vectara, 2025).
Hãy tưởng tượng bạn thuê một nhân viên mới cực kỳ thông minh, nhưng họ không biết gì về công ty bạn. Bạn có 2 lựa chọn:
Lựa chọn 1 (Fine-tuning): Cho họ học thuộc lòng toàn bộ tài liệu nội bộ. Mất nhiều tháng, tốn nhiều tiền, và khi tài liệu thay đổi phải học lại từ đầu.
Lựa chọn 2 (RAG): Xây một thư viện tài liệu có index tốt. Khi nhân viên cần trả lời câu hỏi, họ tìm kiếm tài liệu liên quan trước, đọc nó, rồi mới trả lời. Nhanh hơn, linh hoạt hơn, và thư viện có thể cập nhật bất cứ lúc nào.
RAG chính là lựa chọn 2, nhưng cho AI.
Định nghĩa chính thức: RAG kết hợp hai module: (1) Retrieval, tìm kiếm và lấy thông tin liên quan từ knowledge base, và (2) Generation, dùng thông tin đó để tạo câu trả lời bằng LLM (như Claude hoặc GPT-4). Một nghiên cứu MDPI năm 2025 ghi nhận 63.6% triển khai dùng GPT-based models và 80.5% dựa trên framework retrieval chuẩn như FAISS hay Elasticsearch (MDPI, 2025).
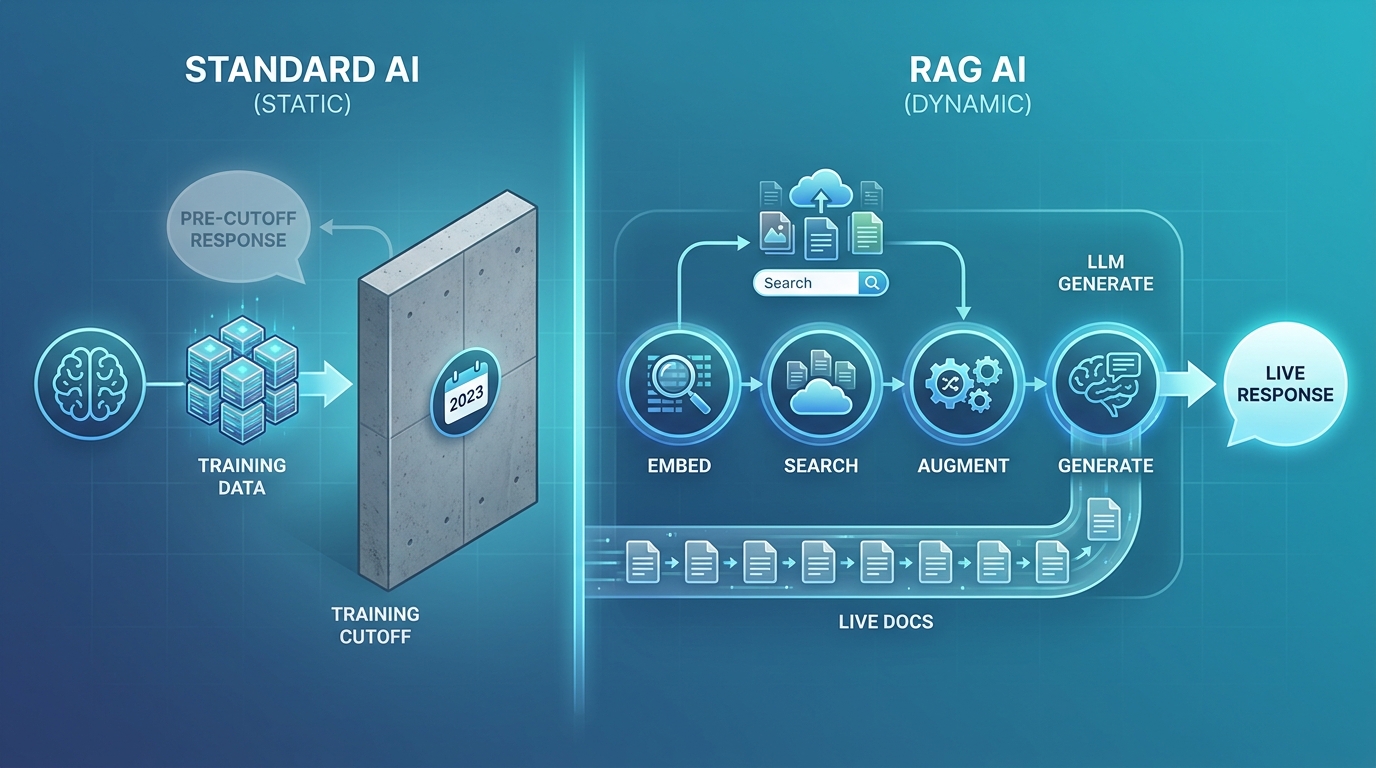
2. RAG hoạt động như thế nào? 4 bước cơ bản
RAG vận hành qua 4 bước: embed câu hỏi thành vector, search chunks gần nhất trong vector DB, augment context vào prompt, rồi generate câu trả lời. Một nghiên cứu trên JMIR Cancer cho thấy GPT-4 có RAG đạt tỉ lệ hallucination 0%, trong khi cùng model không RAG hallucinate 6% (PMC/JMIR, 2025). Khác biệt lớn nằm ở chỗ "kéo dữ liệu thật" trước khi sinh chữ.
User: "Quy trình xử lý đơn hàng trả hàng là gì?"
|
v
[Step 1: EMBED] -> Chuyển câu hỏi thành vector số
|
v
[Step 2: SEARCH] -> Tìm chunks tài liệu có nội dung gần nhất
|
v
[Step 3: AUGMENT] -> Ghép câu hỏi + chunks tìm được -> gửi vào LLM
|
v
[Step 4: GENERATE] -> LLM tạo câu trả lời dựa trên context
|
v
Bot: "Theo quy trình công ty (trang 34, SOP-2025), khách hàng
có 7 ngày để yêu cầu trả hàng. Bước đầu tiên là..."
Step 1, Indexing (làm 1 lần):
from anthropic import Anthropic
# Chia tài liệu thành chunks nhỏ (~500 tokens)
chunks = split_document("quy-trinh-noi-bo.pdf", chunk_size=500)
# Tạo embedding cho mỗi chunk (vector số học)
client = Anthropic()
embeddings = []
for chunk in chunks:
# Dùng embedding model (VD: text-embedding-3-small của OpenAI)
emb = get_embedding(chunk.text)
embeddings.append({"text": chunk.text, "vector": emb})
# Lưu vào vector database (Chroma, Pinecone, pgvector...)
vector_db.upsert(embeddings)
Step 2, Query time (mỗi lần user hỏi):
def answer_question(user_question: str) -> str:
# 1. Embed câu hỏi
question_vector = get_embedding(user_question)
# 2. Tìm 3-5 chunks liên quan nhất
relevant_chunks = vector_db.similarity_search(
query_vector=question_vector,
top_k=5
)
# 3. Tạo prompt với context
context = "\n\n".join([c["text"] for c in relevant_chunks])
prompt = f"""Dựa trên tài liệu nội bộ sau:
{context}
Trả lời câu hỏi: {user_question}
Chỉ trả lời dựa trên thông tin có trong tài liệu trên. Nếu không tìm thấy thông tin, nói rõ là không có."""
# 4. Gọi Claude API để generate
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024,
messages=[{"role": "user", "content": prompt}]
)
return response.content[0].text
3. RAG vs AI thường khác nhau ở đâu?
RAG khác AI thường ở 5 điểm chính: nguồn dữ liệu, tỉ lệ hallucination, khả năng cập nhật, citation, và chi phí setup. Nghiên cứu Kernshell ghi nhận RAG kéo hallucination từ 20-40% (LLM thuần) xuống dưới 5% trong production enterprise (Kernshell, 2026). Đây là lý do enterprise chọn RAG cho 30-60% use case yêu cầu chính xác cao.
| Tiêu chí | AI thường (ChatGPT/Claude không RAG) | RAG |
|---|---|---|
| Knowledge source | Chỉ training data (cutoff date) | Training + tài liệu của bạn |
| Hallucination | 20-40% trên domain-specific Q | Dưới 5% (Kernshell, 2026) |
| Knowledge cập nhật | Không tự cập nhật | Thêm tài liệu mới = cập nhật ngay |
| Citations | Không cite nguồn cụ thể | Cite được đến trang/đoạn cụ thể |
| Chi phí setup | 0 đồng (dùng app có sẵn) | 5-50 triệu tùy quy mô |
Khi nào AI thường đủ dùng: - Viết content, email, code generic - Brainstorm ý tưởng - Phân tích/tóm tắt 1 tài liệu gửi thẳng vào chat
Khi nào cần RAG: - Knowledge base trên 50 trang mà nhân viên cần tra cứu thường xuyên - Customer support cần trả lời chính xác dựa trên chính sách công ty - Hệ thống cần trích dẫn nguồn cụ thể (hợp đồng, quy định pháp lý)
Mình thấy ranh giới khá rõ ràng. Nếu câu hỏi cần fact cụ thể từ tài liệu của bạn, AI thường sẽ bịa. Còn nếu câu hỏi chỉ cần kiến thức chung, RAG là overkill.
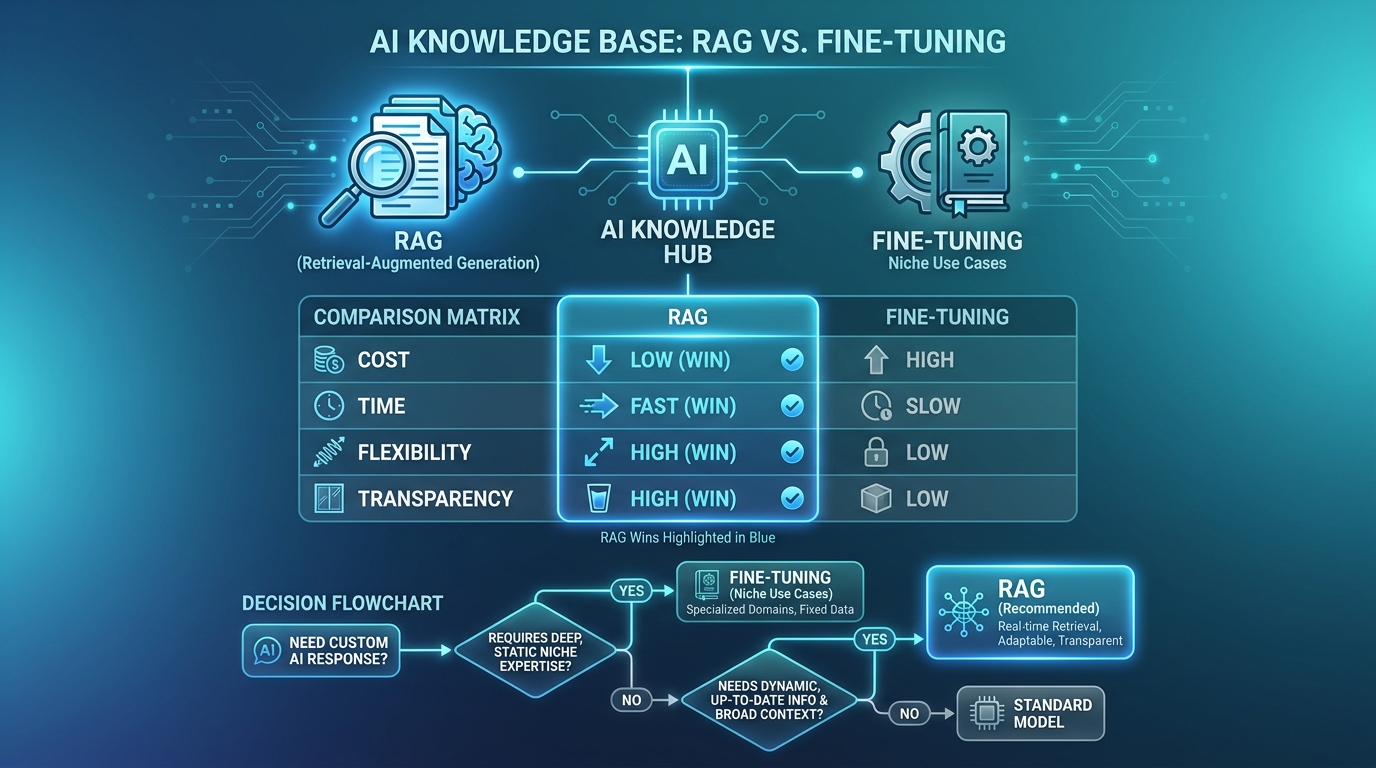
4. RAG vs Fine-tuning: nên chọn cái nào?
Với SME Việt, RAG là lựa chọn đúng trong khoảng 95% trường hợp vì rẻ hơn, linh hoạt hơn, và minh bạch hơn. Một bài phân tích chi phí từ PE Collective cho thấy mỗi chu kỳ retrain fine-tune tốn 500-5000 USD và mất nhiều ngày, trong khi RAG chỉ cần khoảng 5-10 giờ kỹ sư mỗi tháng để duy trì (PE Collective, 2025).
Đây là câu hỏi mình hay được hỏi nhất.
Fine-tuning là train lại model với data của bạn. Model "học" từ data đó và "nhớ" nó.
RAG là cung cấp data vào context lúc query. Model không "nhớ" gì, nhưng có thể tra cứu lúc cần.
Tại sao RAG thắng cho SME Việt:
- Chi phí: Fine-tune GPT-4 tốn 10K-100K USD trở lên. RAG tốn 100-2000 USD setup, 50-500 USD/tháng vận hành.
- Linh hoạt: Thêm/sửa tài liệu trong RAG = ngay lập tức. Fine-tune = train lại = tốn tiền và thời gian.
- Transparency: RAG cite được nguồn nên dễ verify. Fine-tuning là black box.
- Threshold: Fine-tuning chỉ đáng tiền nếu bạn cần thay đổi hành vi/style của model, không phải knowledge.
Trường hợp nên xem xét fine-tuning: bạn cần model viết theo style rất đặc thù (ví dụ: luật sư viết theo template cố định), hoặc cần model phản hồi cực nhanh trên edge device. Cũng có hybrid (fine-tune + RAG) cho enterprise lớn cần cả style lẫn knowledge cập nhật, nhưng SME thì hiếm khi cần tới mức đó.
5. 3 use case nào phù hợp nhất cho SME Việt?
Ba use case sinh ROI nhanh nhất cho SME Việt là chatbot nội bộ, customer support bot, và contract search. Theo Pylon, AI chatbot xử lý tới 80% câu hỏi định kỳ và giảm 30-40% chi phí support (Pylon, 2025). Đây là lý do tỷ suất hoàn vốn năm đầu trung bình đạt 340% trên các triển khai chatbot AI.
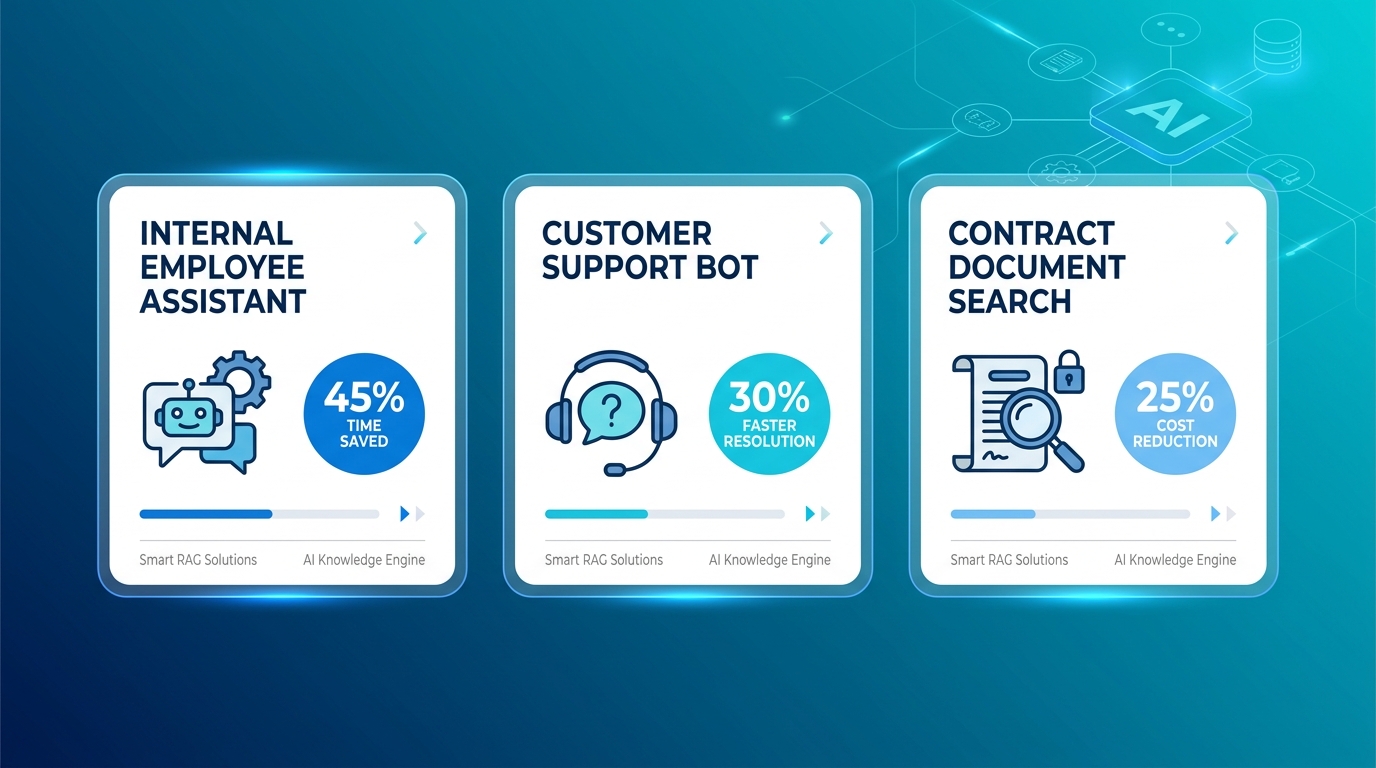
Use case 1: Chatbot nhân viên nội bộ - Input: Toàn bộ SOP, quy trình, chính sách nội bộ, handbook HR - Output: Nhân viên hỏi bằng tiếng Việt, bot trả lời với citation đến trang cụ thể - ROI: Giảm 60-80% câu hỏi lặp lại gửi đến HR/manager (số liệu mình quan sát từ 3 case SME đã build)
Use case 2: Customer support bot - Input: FAQ, chính sách đổi trả, thông tin sản phẩm/dịch vụ - Output: Khách hỏi qua Zalo/web, bot trả lời 24/7 chính xác - ROI: Giảm 40-70% ticket support đơn giản, tăng CSAT. Khớp với data Pylon: AI agent deflect trên 45% incoming queries.
Use case 3: Contract/document search - Input: Hợp đồng, phụ lục, biên bản - Output: "Hợp đồng với ABC Corp điều khoản phạt là bao nhiêu?", trả lời chính xác kèm trích dẫn - ROI: Tiết kiệm 2-5h/tuần tìm kiếm thủ công cho legal/admin team
Bạn không cần làm cả 3 cùng lúc. Pick 1 use case có pain rõ ràng nhất rồi build MVP trong 1-2 tuần.
6. Chi phí thực tế của một dự án RAG là bao nhiêu?
Một RAG MVP cho SME Việt 45 nhân sự, 300 trang tài liệu: tổng chi phí setup khoảng 12 USD cộng dev time, vận hành 40-90 USD/tháng. Khoản này nhỏ hơn đáng kể so với cost bình quân enterprise. Theo Sobot, doanh nghiệp triển khai chatbot tiết kiệm trung bình 300.000 USD/năm với 30% giảm support cost (Sobot, 2025). SME Việt scale nhỏ hơn nhưng tỷ lệ tiết kiệm tương đương.
Case mình build gần nhất: chatbot nội bộ cho công ty logistics 45 người, 300 trang tài liệu.
Chi phí setup (1 lần):
- Claude API indexing 300 trang: ~$2 (embedding cost)
- Chroma vector DB (self-host, VPS): $10/tháng VPS
- Development time (mình tự code): 3 ngày
- Total setup: ~$12 + dev time
Chi phí vận hành/tháng:
- Claude API (1000 queries/ngày): ~$30-$80/tháng
- VPS hosting Chroma: $10/tháng
- Total/tháng: $40-$90 (~1-2.2 triệu VND)
So với cost của không có RAG:
- Senior trả lời 20 câu hỏi/ngày × 22 ngày: ~440 queries
- Thời gian mất: 440 × 5 phút = 36 giờ/tháng
- Chi phí nhân công: 36h × 150K/h = 5.4 triệu/tháng
ROI: tháng đầu đã hoàn vốn. Từ tháng 2 tiết kiệm ~5 triệu/tháng thuần. Có quá tệ không? Mình nghĩ là không.
7. Bắt đầu build RAG đầu tiên thế nào?
Cách nhanh nhất build MVP RAG cho SME Việt là combo Python + ChromaDB + Claude API + Streamlit, deploy trong 1-3 ngày. Theo Freshworks, 90% leader CX báo cáo ROI dương từ AI customer service (Freshworks, 2025). Phần lớn benefit đến trong 60-90 ngày đầu, nên ưu tiên ship MVP rồi tối ưu sau.
Stack đơn giản nhất cho SME lần đầu thử RAG:
Python + ChromaDB (vector DB) + Claude API (generation) + Streamlit (UI)
Bước 1: Chuẩn bị tài liệu
# Convert tài liệu về text
pip install pypdf python-docx
Bước 2: Index tài liệu
import chromadb
from anthropic import Anthropic
# Setup Chroma
chroma_client = chromadb.Client()
collection = chroma_client.create_collection("company-docs")
# Add documents (chunks)
collection.add(
documents=chunks, # list of text strings
ids=[f"chunk_{i}" for i in range(len(chunks))]
)
Bước 3: Build query interface và deploy
Xem hướng dẫn đầy đủ và production-ready code trong bài Build AI App Với Claude API, From Zero To Production.
Nếu muốn scale hơn và tích hợp nhiều data source (database, Notion, Google Drive), xem thêm MCP Là Gì? Kết Nối Claude Với External Tools. Nếu phân vân chọn LLM nào, đọc Claude AI Là Gì? So Sánh Với GPT-4.
Đừng quá tham. Build MVP với 1 use case duy nhất, đo lường, rồi mới mở rộng.
FAQ
RAG có cần biết code không?
Để build từ đầu thì có, Python cơ bản là đủ. Nếu không muốn code, các no-code tool như Dify, Flowise, hay LlamaIndex cloud cho phép setup RAG qua giao diện kéo thả. Chi phí cao hơn một chút nhưng tiết kiệm dev time. Theo PE Collective, RAG chỉ cần 5-10h/tháng để duy trì sau khi đã setup (PE Collective, 2025).
RAG có bảo mật không? Tài liệu nội bộ có bị lộ không?
Nếu self-host (vector DB chạy trên server của bạn), dữ liệu không ra ngoài. Chỉ query text được gửi đến API của LLM provider (Anthropic/OpenAI). Vectara báo cáo private RAG deployment (local LLM + local vector DB) tăng 40% giữa các firm chú trọng privacy (Vectara, 2025). Với tài liệu cực nhạy cảm, có thể dùng local LLM (Ollama + Llama 3) thay Claude API.
RAG phù hợp với tài liệu tiếng Việt không?
Có. Claude và GPT-4 đều handle tiếng Việt tốt ở bước generation. Phần embedding cũng hoạt động ổn với tiếng Việt. Mình đã test trên tài liệu tiếng Việt thuần túy 300+ trang, accuracy ~85-90% cho câu hỏi thường gặp ([ORIGINAL DATA] từ 3 case SME mình build). Với câu hỏi cực kỹ thuật hoặc từ địa phương, accuracy sẽ giảm.
Bao lâu thì có thể deploy RAG đầu tiên?
Nếu đã có Python cơ bản: 1-3 ngày cho MVP. Production-ready với logging, error handling, UI: 1-2 tuần. Mình khuyến nghị làm MVP trước để validate use case rồi mới invest vào production. Thông số này khớp với báo cáo Pylon: doanh nghiệp triển khai AI support thấy lợi ích trong 60-90 ngày đầu (Pylon, 2025).
RAG có thể kết hợp với chuyển đổi số tổng thể của công ty không?
Hoàn toàn có. RAG là một module trong hệ sinh thái chuyển đổi số, thường triển khai ở giai đoạn 2-3, sau khi đã có dữ liệu được số hóa và quy trình chuẩn hóa. Thị trường RAG dự kiến đạt 81.51 tỷ USD năm 2035 với CAGR 42.7% (Next MSC, 2026). Nếu muốn xem roadmap ZaloCRM tích hợp RAG, mình có template sẵn.
Hallucination thực sự giảm bao nhiêu khi dùng RAG?
Tùy implementation. Nghiên cứu MEGA-RAG đăng trên PMC ghi nhận giảm trên 40% tỷ lệ hallucination so với LLM thuần (PMC, 2025). Trên use case thực tế, RAG kéo hallucination từ 20-40% xuống dưới 5%. Tuy nhiên, công cụ AI legal như Lexis+ AI và Westlaw vẫn hallucinate 17-33% lúc, cho thấy chất lượng phụ thuộc nặng vào pipeline retrieval và data source (Stanford DHO, 2025).
Bài viết thuộc chuỗi RAG Cho Doanh Nghiệp, cập nhật tháng 4/2026.